
Decoding a partial QR code
While practicing the alphabet with my daughter we came across the following image for ‘Q’:

I picked up my phone to try to scan it. Unfortunately too much of the the data was obscured. :-( This got me thinking though, what on earth did the author choose put in that code. Was it a random image from the web? A hidden message? A link to a secret page with a huge prize to the person who first cracked the code?! My curiosity slowly evolved into an obsession.
Cleaning up what was available
I knew that all QR codes had some degree of redundancy and that partially obscured images should be decodable. Maybe it would be enough to clear up the image and complete the corner squares…

Unfortunately my QR reader still couldn’t handle it.
Format Code
After begging the Reddit community for help I decided to take a look at the bits myself to see if there was any chance I could decode it by hand. The first thing to identify was the QR format and version information. This information is encoded along the sides of the top left square (and copied along side the bottom and right edges of the right and bottom squares). Luckily these bits were intact!

From this I could tell that the QR code was of Version 3, had Mask Pattern 3 and Error Correction Code Level ‘M’. The mask pattern is a bit pattern that is used to XOR the entire data to avoid having unintentional alignment squares where they shouldn’t appear. The pattern in this particular case turned out to look as follows:

XORing the data with this pattern yielded the following image:

Still obviously didn’t tell me much, but these were supposed to be the actual bits.
Looking at the data
The sequence of bits is layed out in a somewhat crazy zig-zag pattern starting from the lower right corner:

Unfortunately the first bits in the sequence where not available. These bits tell the encoding (numeric, alphanumeric, binary or Kanji) and the length of the payload. The most common encoding seemed to be binary which is 8-bit ASCII, so I assumed this was the case and continued to group the remaining bit sequence in octets:

The bits of the first octets where unknown, so I started at the 5th character. 01110011 should be an s. Next character I got was a :. (Could it perhaps be https://...??) Two unknown characters followed then w… w… w… .… Bingo, a URL! Apparantly I got the bit mask and the alignment of the octets right and correctly guessed the encoding! I kept going, f… a… c… e… b… Well, you guessed it. It was a Facebook address.
I filled in the bits corresponding to http and // to see if it was enough for any of my QR scanners (by now I had 6 different installed on my phone). Unfortunately it wasn’t.
Continuing the decoding
I kept going, and when I was finished I had the following:
| Character | Possilibities |
|---|---|
| 1 | h |
| 2 | t |
| 3 | t |
| 4 | p |
| 5 | s |
| 6 | : |
| 7 | / |
| 8 | / |
| 9 | w |
| 10 | w |
| 11 | w |
| 12 | . |
| 13 | f |
| 14 | a |
| 15 | c |
| 16 | e |
| 17 | b |
| 18 | o |
| 19 | o |
| 20 | k |
| 21 | . |
| 22 | c |
| 23 | o |
| 24 | m |
| 25 | / |
| 26 | Unknown |
| 27 | a or ! |
| 28 | s |
| 29 | k |
| 30 | ', /, G, g, O or o |
| 31 | j |
| 32 | a |
| 33 | j, k, n or o |
| 34 | Unknown |
| 35 | Unknown |
| 36 | e |
| 37 | f |
| 38 | < or = |
| 39 | Unknown |
| 40 | Unknown |
| 41 | Unknown |
| 42 | Unknown |
I had no idea where the string ended (except that after around 42 characters the ECC begun). My friend told me to check the publishers facebook page. The name of the publisher was LäsKojan and laskojan could actually fit! I filled in a few missing bits to see if any QR scanner would accept it, to no avail. I tried to brute force it by guessing a couple of thousand combinations for the unknowns to see if I could get a match with the original one, but that failed too.
The padding bytes!
I turned back to the spec and noted that it mandated that the data was to be padded with 0x11 0xEC 0x11 0xEC…. Indeed the bit sequence ended with the these bits:
01100101 011001100 011110___ _________ ______000 11101100 00010001I also noted that the byte before the last two could not be a part of the padding since it ended with 000. Now I knew where the payload ended and could thus fill in the length bits in the lower right corner. Unfortunately still none of my QR scanners where able to scan the code :-(
Staring at the letters
What puzzled me at this point was that the odd looking < or = characters at position 38 had to be part of the string. Why include such garbage if the publishers webpage was https://www.facebook.com/laskojan?! The = could of course come after a query param. If so, character 34 would have to be a ?, character 35-37 would be a query parameter and character 39-40 would be a suitable value: ?_ef=__. Some googling showed that Facebook URLs can indeed have a ref parameter and is most often set to ts for “top search”!
https://www.facebook.com/laskojan?ref=tsAgain, I tried to fill in the bits corresponding to my guess, but still to no avail, and generating the corresponding QR code did not match the original one.
Error Correction should cover this!
I started counting the missing bits. According to the spec ECC level ‘M’ is capable of handling up to 15% missing bits. Out ouf the ~270 bits I was only uncertain about 66 bits (~24%). By randomly guessing those bits, it should be possible to get half of them right. That would get it down to ~12% errors. It really ought to work!
I held up my phone towards the screen and started to randomly flip the unknown bits. Suddenly a beep! My scanner had managed to decode the QR image!
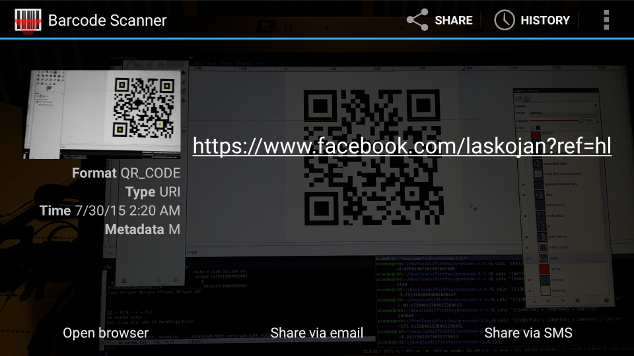
The value of the ref param was apparantly hl! I put that exact URL in my QR code generator and BAM, the resulting image matched the original QR code.

Unfortunately no link to a secret webpage and no prize to collect (see below!) But it was extremely satisfying to finally crack it! :-) Now, back to the original challenge; teaching my daughter the letters… ;-)
P.S. I posted link to this page on the publishers webpage. They repsonded with this:

Translation: Nice with so curious and engaged readers! Of course the first person to crack the code should have a prize! Email us your address and we’ll send you one of LäsKojans other children books to you and your daughter.